Knowledge Base Details
This page contains the key information about your Web based / manual data ingestions.
What this page does
- Define content to ingest: You provide the web addresses (URLs) that make up your knowledge base.
- Start & monitor ingestion: You run a crawl and check its live status from here.
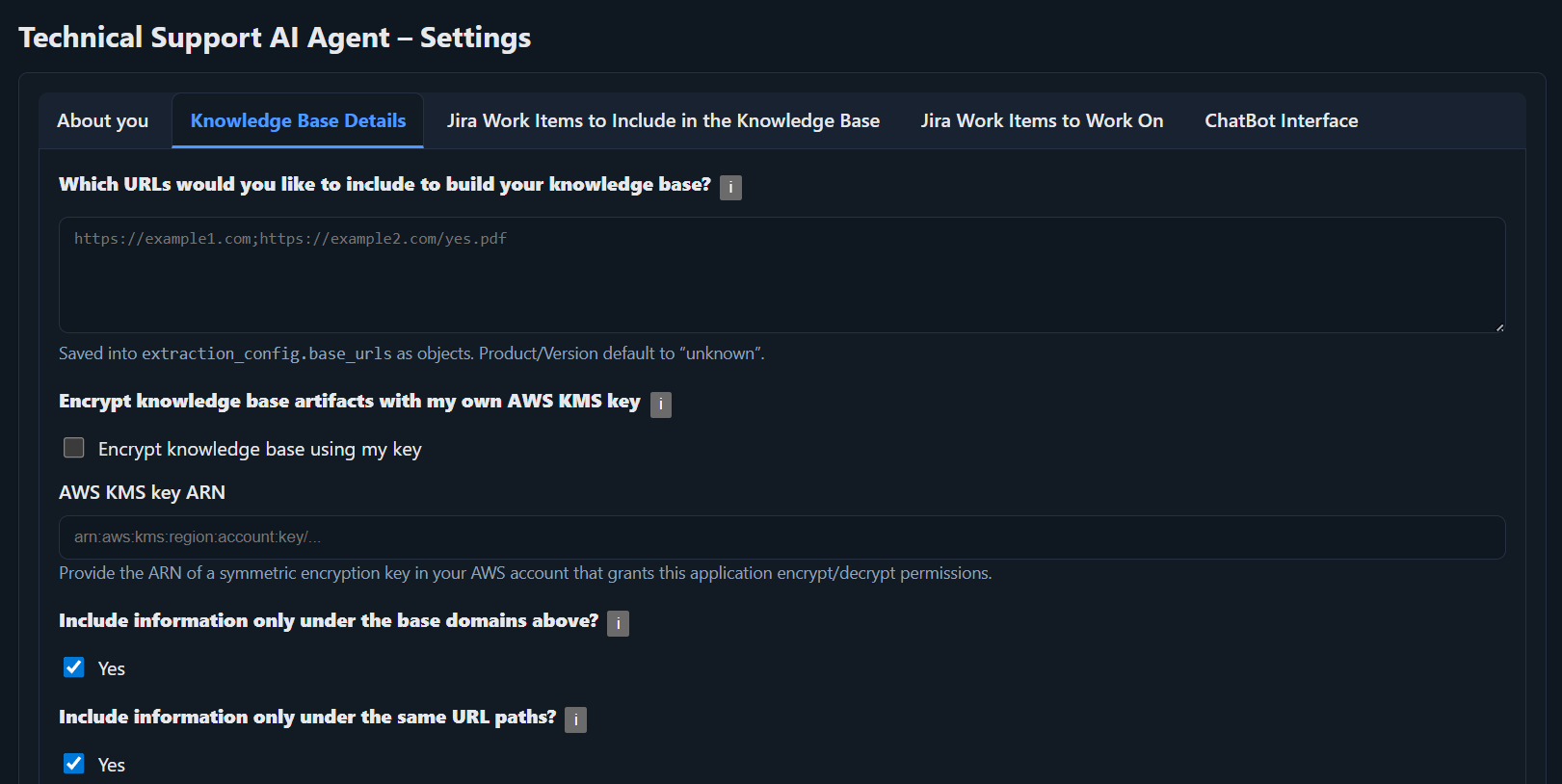
Which URLs would you like to select?
Enter one URL per line, followed by Product and Version information for the relevant product. Each URL tells the application where to gather information. The first part is the URL to ingest. The second and third parts (optional) indicate the related product and version. If your URL is not specific to a product, you can leave those labels empty for those URLs.
Format
https://docs.solverox.com/TSAIAgent/|TSAIAgent|V3.1
https://docs.solverox.com/EasyReports/|EasyReports|V1.0/ (slash), regardless of how they appear on the web.
Encrypt knowledge base artifacts with my own AWS KMS key
You can protect your information (content chunks and any JQLs that might include your customer names) with your own encryption key. If you enable this option, provide your AWS KMS ARN so the AI Agent can encrypt with your key.
Include information only under the base domains above
Limits ingestion to the same domain. For example, if you specified https://docs.solverox.com/TSAIAgent/ as one of your URLs, links pointing outside docs.solverox.com will be ignored.
Include information only under the same URL paths
Limits ingestion to the same path. For example, if you specified https://docs.solverox.com/TSAIAgent/, as one of your URLs, links pointing outside docs.solverox.com/TSAIAgent/ will be ignored.
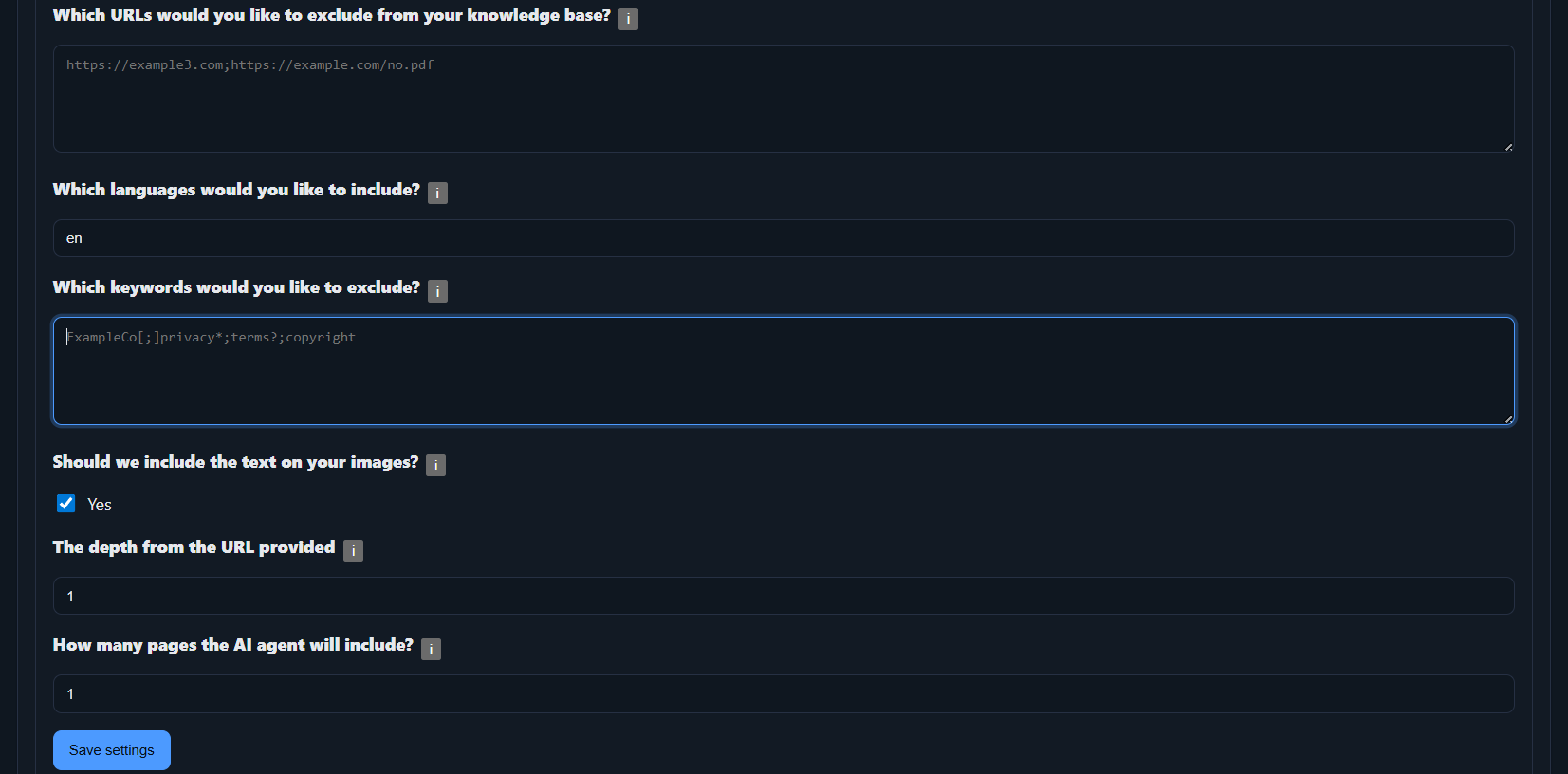
Which URLs would you like to exclude?
Provide specific URLs you do not want ingested. If the crawler encounters them, those pages are skipped. Example:
https://docs.solverox.com/TSAIAgent/settings/Which languages would you like to include?
If your site uses language codes (hreflang) and you want only selected languages ingested, list them here.
Which keywords would you like to exclude?
Use this field to filter out patterns via regular expressions (regex). Separate each expression with the three-character sequence [;].
Copyright 2025 Solverox Inc. All rights reserved.[;]Copyright[;]previous[;]next[;]Solverox[;]Skip to main pageShould we include the text on your images?
If enabled, the application will extract text from all images (OCR) found during the ingestion process and add it to your knowledge base.
The depth from the URL provided
Choose how many link levels to follow from the starting URL. Example for https://docs.solverox.com/TSAIAgent/ with depth = 1:
https://docs.solverox.com/TSAIAgent/something.html -> OK
https://docs.solverox.com/TSAIAgent/dept1/something1.html -> OK
https://docs.solverox.com/TSAIAgent/dept1/something2.html -> OK
https://docs.solverox.com/TSAIAgent/dept1/depth2/something.html -> NOT OKHow many pages should be included?
Set a maximum number of pages to ingest per run (e.g., 100). This caps the volume and helps you stay within your plan.
Extraction Controls
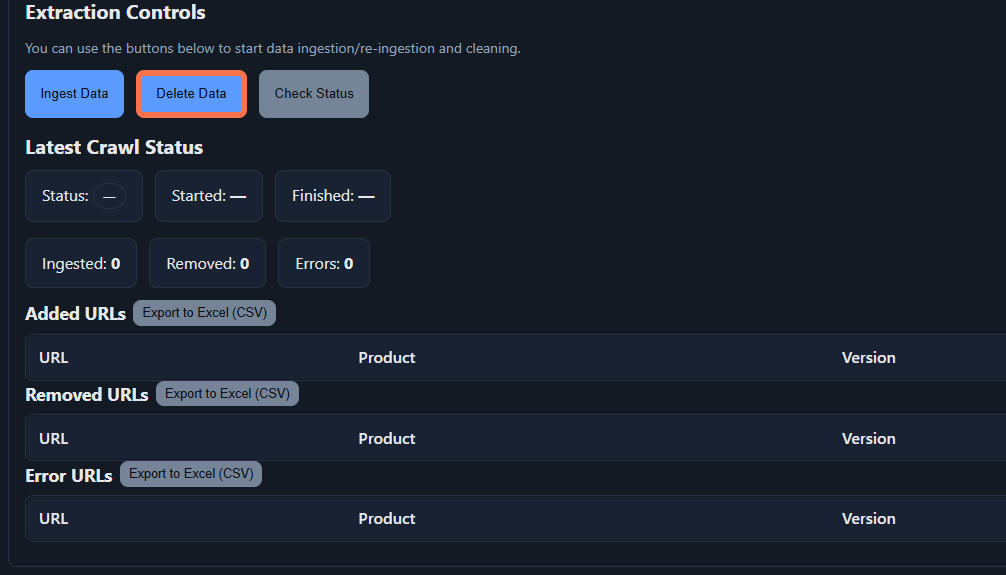
- Ingest Data: Starts a new ingestion. Content matching your settings starts being ingested.
- Delete Data: Deletes the data from your knowledge base. It still uses the definition we mentioned above.
- Check Status: Displays real-time progress. When ingestion finishes, the status turns to "idle".
- Added URLs, Removed URLs and Error URLs tables: Shows the result of the ingestion/data cleaning.
If you want to start small
Configure a single, well-scoped URL so you can validate the ingestion pipeline before scaling out:
https://docs.solverox.com/TSAIAgent/|TSAIAgent|V3.1- Stick with the same base path and domain.
- List keywords to exclude recurring boilerplate.
- Avoid OCR unless the documents truly require it.
- Provide realistic depth and max-page values so the crawl completes.
Once you work through this guide, switch the app ON and start ingestion. That small experiment gives you confidence in how URL ingestion behaves before you expand coverage.
Save your settings
Click Save Settings to keep the changes.